



BP算法与深度学习主流优化器(Adam,RMSprop等等)的区别是什么?
编辑:佚名 日期:2024-04-08 06:44 / 人气:
最近在研究深度学习,之前对神经网络有所了解,知道BP之于神经网络的地位,但是深度学习的模型中却很少用到BP算法去训练模型参数,CNN倒是用到了BP算法,想知道BP算法与深度学习主流优化器(RMSprop,SGD,Adam等)的区别是什么
BP算法是其他主流优化方法的基础。
SGD是指用随机使用单个样本执行BP算法,一般机器学习框架中的SGD优化器事实上是mini-batch的SGD。
Adam、RMSprop是对SGD的改造,具有自动调节学习速率的能力。不仅仅考虑当前的梯度,还会考虑之前的累计梯度。
bp是反向传播的缩写,其他算法都是基于梯度的反向传播来更新模型参数的。只是说更新的时候有的算法更新的快一些有的更新的慢一些而已。
l.SGD
随机梯度下降法是梯度下降法的一个小变形,就是每次使用一批 (batch) 数掘进行 梯度的计算,而不是计算全部数据的梯度.因为现在深度学习 的数据量都特别大, 所以 每次都计算所有数据的梯度是不现实的,这样会导致运算时间特别长,同时每次都计 算全部的梯度还失去了一些随机性, 容易陷入局部误差,所以使用随机梯度下降法可 能每次都不是朝着真正最小的方向.但是这样反而容易跳出局部极小点c
2.Momentum
第二种优化方法就是在随机梯度下降的同时,增加动量 (Momentum)ε 这来自于物 理中的概念, 可以想象损失 函数是一个山谷,→个球从山谷滑下来 ,在一个平坦的地 势,球的滑动速度就会慢下来,可能陷入一些鞍点或者局部极小值点,如下图所示
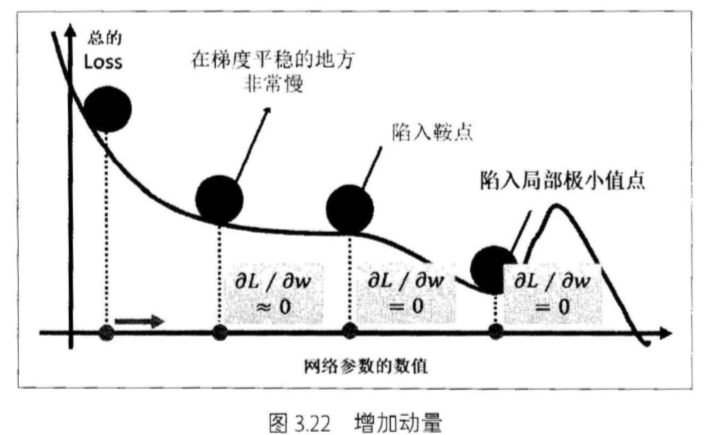
这个时候给它增加动量就可以让它从高处滑落时的势能转换为平地的功能,相当 于惯性增加 f小球在平地滑动的速度,从而帮助其跳出鞍点或者局部极小点c
动量怎么计算呢?动量的计算基于前面梯度,也就是说参数更新不仅仅基于当前 的梯度,也基于之前的梯度,可以用图3.23来简单地说明c
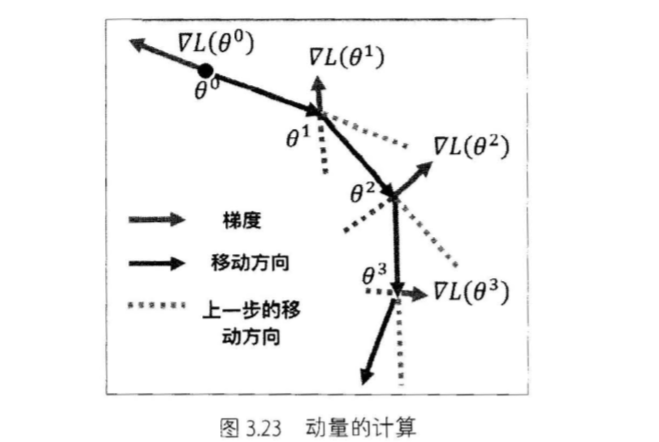
记住我们更新的是梯度的负方向,红色表示梯度,蓝色表后更新方向,闺中绿色的 虚线就是动量,可以看到也就是之前→次梯度的负万向 c
除此之外,对于动量还有一个变形, 即 Nesterovo 我们在更新参数的时候需要计算 梯度,传统的动量方法是计算当前位置的梯度,但是 Nesterov 的方法是计算经过动量 更新之后的位置的梯度 士
3.Adagrad
这是一种 自适应学习率 (adaptive) 的方法,它的公式是 :
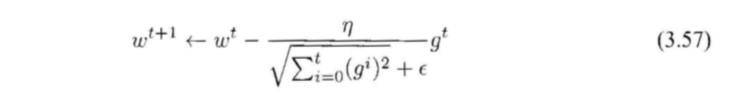
通过式 (3.57 ) ,我们可以看到学习率在不断变小, 且受每次计算出来的梯度影响 ,对于梯度 比较大的参数,它的学习率就会变得相对更小 ,里面的根号特别重要,没有这个根号算法表现非常差c 同时 E 是一个平滑参数,通常设置为 10e-4 ~ 10e-8 ,这是为了避 免分母为 0
自适应学习率的缺点就是在某些情况下一直递减的学习率并不好这样会造成学习过早停止。
4.RMSprop
这是一种非常有效的 自适应学习率的改进方法,它的公式是 :

这里多了一个 α,这是一个衰减率,也就是说 RMSprop 不再会将前面所有的梯度平方 求和,而是通过一个衰减率将其变小,使用了一种滑动平均的方式,越靠前面的梯度对 自适应的学习率影响越小,这样就能更加有效地避免 Adagrad 学习率一直递减太多的 问题,能够更快地收敛。
5.Adam
这是一种综合型的学习方法,可以看成是阳v1Sprop 加上动量 (Momentum) 的学习 方法,达到比 RMSProp 更好的效果。
以上介绍了多种基于梯度的参数更新方法,实际中我们可以使用 Adam 作为默认 的优化算法,往往能够达到比较好的效果,同时 SGD十Momentum 的方法也值得尝试。
引用自:《深度学习入门之Pytorch》
github:SherlockLiao/code-of-learn-deep-learning-with-pytorch
- BP算法指的是误差逆传播算法,重点是将误差反向传播进行权重的调整;
- 优化器可以理解为最小化/最大化目标函数的求解器,通过优化器我们可以学习到未知函数什么样子的参数能使目标函数最小/最大。
BP算法对权值的更新是基于梯度下降策略的,而梯度下降的目的就是最小化目标函数,又Adam、RMSprop就是利用的梯度优化参数的,所以可以使用Adam、RMSprop等优化器去求解参数。
我们知道,深度学习可以归结为一个优化问题,最小化目标函数 ;而求解过程首先需要求解目标函数的梯度
,然后将参数$θ$向负梯度方向更新,
,
为学习速率,表明梯度更新的步伐大小。
最优化的过程依赖的算法称为优化器,可以看出深度学习优化器的两个核心是梯度与学习率,前者决定参数更新的方向后者决定参数更新步长。深度学习优化器之所以采用梯度(我们知道梯度就是一阶导数)是因为,对于高维的函数其更高阶导的计算复杂度大,应用到深度学习的优化中不实际。
BP算法即Back propagation,反向传播算法。是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
反向传播要求有对每个输入值期望得到的已知输出,来计算损失函数的梯度。因此,它通常被认为是一种监督式学习方法,虽然它也用在一些无监督网络(如自动编码器)中。它是多层前馈网络的Delta规则的推广,可以用链式法则对每层迭代计算梯度。反向传播要求人工神经元(或“节点”)的激励函数可微。
随机梯度下降法(stochastic gradient descent):
stochastic是相对于batch来说的,SGD在每次更新时只用1个样本而不是所有样本,用样本中的一个例子来近似我所有的样本,来调整参数θ。虽然相对于因而随机梯度下降是会带来一定的问题,因为计算得到的并不是准确的一个梯度,对于最优化问题,凸问题,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。如下图:

但是相比于batch,随机的方法更快,更快收敛,虽然不是全局最优,但很多时候是我们可以接受的,所以这个方法用的也比上面的多。下图是其更新公式:
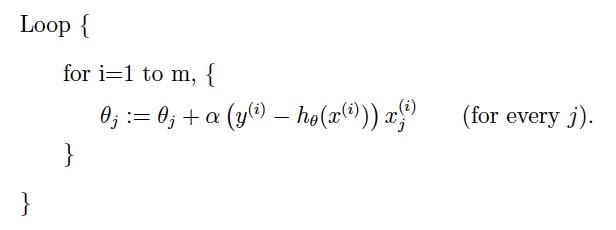
不过在深度学习中,我们最常用的是mini-batch的方法,它介于stochastic和batch之间。
动量梯度下降法(Gradient descent with Momentum)
动量梯度下降法的运行速度几乎总是快于标准的梯度下降算法。简而言之,其基本的想法就是计算梯度的指数加权平均数,并利用该梯度更新你的权重。
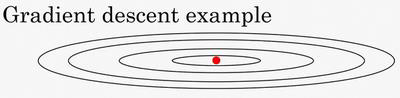
例如,你要优化成本函数,形状如图。红点表示最小值的位置,如果我们使用梯度下降法进行迭代,无论是batch还是mini-batch,每次迭代都会上下或者左右波动,如下图所示:
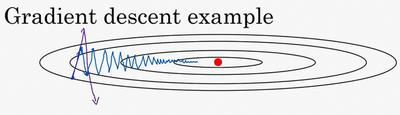
这种上下或者左右的波动减缓了梯度下降法的速度,使得我们无法使用更大的学习速率来更新参数。为了避免这种过度的摆动,我们使用动量梯度下降法。使用梯度的指数加权平均数来进行迭代。要做的计算就是 ,然后重新赋值权重,
,同样的
。这样就可以减缓波动的幅度,从而可以更快的收敛到最优值。
RMSprop(root mean square prop):
算法,它也可以加速梯度下降,我们来看看它是如何运作的。
在之前的例子中,如果你执行梯度下降,虽然横轴方向正在推进,但纵轴方向会有大幅度摆动,为了分析这个例子,假设纵轴代表参数 ,横轴代表参数 ,可能有 1、 2或者其它重要的参数,为了便于理解,被称为 和 。
所以,你想减缓 方向的学习,即纵轴方向,同时加快,至少不是减缓横轴方向的学习,RMSprop算法可以实现这一点。
在第 次迭代中,该算法会照常计算当下 mini-batch的微分 ,所以要保留这个指数加权平均数,我们用到新符号 ,而不是
,因此
,澄清一下,这个平方的操作是针对这一整个符号的,这样做能够保留微分平方的加权平均数,同样,
接着RMSprop会这样更新参数值,
我们希望减缓纵轴上的摆动,所以有了
和
,我们希望
会相对较小,所以我们要除以一个较小的数,而希望
又较大,所以这里我们要除以较大的数字,这样就可以减缓纵轴上的变化。
Adam:
Adam优化算法基本上就是将 Momentum和 RMSprop结合在一起。前面已经了解了Momentum和RMSprop,那么现在直接给出Adam的更新策略,

==Adam算法结合了 Momentum和 RMSprop梯度下降法,并且是一种极其常用的学习算法,被证明能有效适用于不同神经网络,适用于广泛的结构。==
你得先算出来梯度才能优化啊…
BP是各种优化方法的基础
内容搜索 Related Stories
推荐内容 Recommended
- 热点17STS(科学、技术、社会)讲义-----2021中考科学热点问题综合学生版+解析.docx06-14
- 基于移动终端的花卉识别系统06-01
- 找一张图片的原图、出处:最全搜图网站及案例分享05-07
- 拍照识花_805-07
- AiCam 04-11

